Python在數(shù)據(jù)科學(xué)中的應(yīng)用 數(shù)據(jù)加載、存儲(chǔ)與文件格式及數(shù)據(jù)分析服務(wù)概述
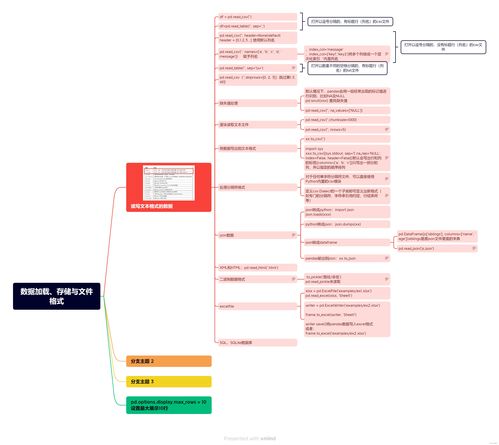
Python在數(shù)據(jù)科學(xué)中的應(yīng)用:數(shù)據(jù)加載、存儲(chǔ)與文件格式及數(shù)據(jù)分析服務(wù)概述
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,Python憑借其強(qiáng)大的生態(tài)系統(tǒng)和簡潔的語法,已成為數(shù)據(jù)科學(xué)領(lǐng)域最受歡迎的工具之一。本文將從數(shù)據(jù)加載與存儲(chǔ)、文件格式選擇以及數(shù)據(jù)分析服務(wù)三個(gè)核心層面,探討Python在數(shù)據(jù)處理流程中的關(guān)鍵作用。
一、數(shù)據(jù)加載與存儲(chǔ)
數(shù)據(jù)加載是數(shù)據(jù)分析的第一步。Python通過多種庫支持從各種來源高效讀取數(shù)據(jù):
- 內(nèi)置文件操作:使用
open()函數(shù)可處理文本文件,但更適合結(jié)構(gòu)化數(shù)據(jù)的是專用庫。
2. Pandas庫:作為數(shù)據(jù)分析的核心工具,Pandas提供了read<em>csv()、read</em>excel()、read<em>json()等函數(shù),支持從CSV、Excel、JSON等多種格式加載數(shù)據(jù)。例如:
`python
import pandas as pd
df = pd.readcsv('data.csv')
`
- 數(shù)據(jù)庫連接:通過
sqlalchemy或pymysql等庫,可從MySQL、PostgreSQL等關(guān)系型數(shù)據(jù)庫加載數(shù)據(jù);pymongo支持MongoDB等NoSQL數(shù)據(jù)庫。
- API與網(wǎng)絡(luò)數(shù)據(jù):
requests庫可用于從Web API獲取JSON或XML格式數(shù)據(jù)。
數(shù)據(jù)存儲(chǔ)同樣重要,Pandas的to<em>csv()、to</em>excel()等方法可將處理后的數(shù)據(jù)保存到文件,而數(shù)據(jù)庫操作庫則支持將數(shù)據(jù)持久化到數(shù)據(jù)庫中。
二、文件格式的選擇與處理
選擇合適的文件格式能提升數(shù)據(jù)處理的效率和性能。常見格式包括:
- CSV(逗號(hào)分隔值):通用性強(qiáng),但缺乏數(shù)據(jù)類型定義,不適合大型數(shù)據(jù)集。
- Excel文件:適合商業(yè)場景,但處理速度較慢,且依賴外部庫。
- JSON:適用于嵌套數(shù)據(jù)結(jié)構(gòu),常用于Web數(shù)據(jù)交換。
- HDF5:支持大型科學(xué)數(shù)據(jù)集,通過
pandas.HDFStore實(shí)現(xiàn)高效存儲(chǔ)。
- Parquet與Feather:列式存儲(chǔ)格式,Parquet兼容Hadoop生態(tài)系統(tǒng),F(xiàn)eather提供更快的讀寫速度。
選擇格式時(shí)需考慮數(shù)據(jù)大小、結(jié)構(gòu)、讀寫速度及跨平臺(tái)兼容性。例如,大數(shù)據(jù)場景下Parquet往往優(yōu)于CSV。
三、數(shù)據(jù)分析和存儲(chǔ)服務(wù)
隨著數(shù)據(jù)規(guī)模增長,本地處理可能遇到瓶頸,此時(shí)可借助云服務(wù):
- 云存儲(chǔ)服務(wù):如AWS S3、Google Cloud Storage,Python的
boto3庫支持直接讀寫S3數(shù)據(jù),實(shí)現(xiàn)無限擴(kuò)展的存儲(chǔ)。
- 數(shù)據(jù)分析平臺(tái):Databricks、Google Colab等提供基于Python的云端分析環(huán)境,集成數(shù)據(jù)處理和機(jī)器學(xué)習(xí)工具。
- 數(shù)據(jù)庫即服務(wù):AWS RDS、MongoDB Atlas等托管數(shù)據(jù)庫服務(wù),可通過Python連接進(jìn)行高效數(shù)據(jù)管理。
- 自動(dòng)化管道:使用Apache Airflow或Prefect等工具,可調(diào)度Python腳本實(shí)現(xiàn)數(shù)據(jù)加載、轉(zhuǎn)換和存儲(chǔ)的自動(dòng)化。
四、實(shí)踐建議
- 對于小型項(xiàng)目,Pandas結(jié)合CSV或Excel足矣;大型數(shù)據(jù)應(yīng)考慮Parquet格式和云存儲(chǔ)。
- 使用虛擬環(huán)境(如conda)管理依賴,確保庫版本兼容。
- 編寫可復(fù)用的數(shù)據(jù)加載函數(shù),提升代碼維護(hù)性。
Python通過豐富的庫和服務(wù)集成,為數(shù)據(jù)加載、存儲(chǔ)和分析提供了靈活高效的解決方案。掌握這些工具,將幫助數(shù)據(jù)科學(xué)家更好地應(yīng)對實(shí)際挑戰(zhàn),從數(shù)據(jù)中提取有價(jià)值的信息。
如若轉(zhuǎn)載,請注明出處:http://m.car163.com.cn/product/61.html
更新時(shí)間:2026-02-13 11:03:20